
英特尔(Intel)的人工智能CPU市场,除有来自GPU业者的竞争,还需面对Google等大客户出走自行开发处理器的问题。因此英特尔选择以横向扩充(Scale-Out)取代纵向扩充(Scale-Up)的系统。像是即将推出的Xeon Phi处理器,便是以多类型的工作处理能力为号召,希望借此赢得更多机器学习业者的青睐。
据Data Center Knowledge网站报导,机器学习系统软体编码的规模化,是一项艰钜的任务。英特尔选择了高效能运算系统及超大规模网路云端应用常见的横向扩充群聚方法(Cluster Approach),处理机器学习的规模化问题。
此外,由于多数人都想要一个能够同时执行机器学习与其他工作的系统,因此英特尔的人工智能CPU解决方案,也将不会只有单一功能。如此看来,高度专业化的Google客制芯片Tensor Processing Unit(TPU),并不会对英特尔造成太大的威胁。
英特尔于2015年11月针对高效能运算需求发表了Xeon Phi处理器。Xeon Phi拥有3 TeraFLOPs双精度(Double Precision)的运算效能,并搭载16 GB MCDRAM记忆体,功率效能是GDDR5的5倍以上。Xeon Phi也是英特尔**专为高度平行工作负载设计的可引导式主处理器。
英特尔指出,比起加速器产品,Xeon Phi提供了更大的可扩展性,并且能应付更多种类的工作负载与配置。
Xeon Phi能够透过英特尔的可扩充系统框架(SSF)提升处理系统规模,且在处理速度达到1.5GHz的同时,还能维持比其他GPU或PCIe多核心系统更低的能源预算。
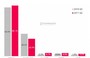
英特尔资料中心副总裁暨高效能运算平台总经理Charles Wuischpard指出,Xeon Phi阵列的速度比起GPU快了1.38倍。而在一个128格的阵列中,Xeon Phi执行深度学习任务的速度是GPU的50倍。
Xeon Phi处理器被寄望能进一步推动深度学习人工智能技术的发展。人工智能的影像与语音辨识功能,已成为许多网路公司业务不可或缺的一部分,而Xeon Phi处理器可望为这些公司带来不少助力。
Xeon Phi与GPU在机器学习的专长,主要在训练领域,而另一个推论(Inference)领域,则早已是Xeon处理器的天下。
除了硬体之外,英特尔也投入了机器学习软体工具及资料库的发展,并开始合作伙伴的训练、为**研究机构推出抢先体验计划(Early Access Program)。目前已有10万名开发人员透过合作计划,正在进行英特尔的机器学习训练。








 公安机关备案号:
公安机关备案号:


