
英特尔(Intel)与NVIDIA正面交锋。人工智慧晶片竞争越来越激烈,Intel于测试报告中指出,新推出的Intel Xeon Phi处理器系列,其运算能力高于目前市面上GPU处理器。针对此份报告内容,NVIDIA不以为然,并以旗下新款专为深度学习打造的运算系统--DGX-1为例,撰写一篇部落格反击Intel,两大人工智慧晶片厂商隔空交火,也使得人工智慧战场更加炽热。
为因应人工智慧时代到来,NVIDIA推出首款深度学习运算系统DGX-1,其采用** NVIDIA Pascal技术支援的Tesla P100加速器打造,并已预先安装多层次应用软体,其中包含可加速所有主要深度学习架构的程式库、NVIDIA Deep Learning SDK、DIGITS GPU训练系统、驱动程式及CUDA。该系统包含容器建立和部署、系统更新及应用程式储存机制的云端管理服务存取。由于结合可在Tesla GPU上执行这些应用软体功能等优势,将其与各类旧版GPU加速解决方案的应用程式执行速度相比,速度*多可快上12倍。
同样积极抢攻人工智慧市场,不让NVIDIA专美于前,Intel于日前发表新一代Intel Xeon Phi处理器系列(代号Knights Mill),支援高效能机器学习与人工智慧。Knights Mill预计2017年问市,除了针对水平扩充分析系统进行*佳化,还将纳入多项关键改良以支援深度学习的训练。现今的机器学习应用方面,Xeon Phi处理器系列所增加的记忆体容量帮助像是百度(Baidu)这样的客户能更容易且有效率的训练其模型。
为强调Xeon Phi处理器的性能优异,Intel于报告中强调该产品与现今GPU处理器之性能差异。报告中指出,Xeon Phi处理器的训练速度比GPU快了2.3倍、Xeon Phi晶片在多个节点的扩展路为38%,且*多可达一百二十八个节点,这是目前市面上的GPU无法办到的。同时,由一百二十八个Xeon Phi处理器组成的系统要比单个Xeon Phi处理器快50倍,意旨Xeon Phi处理器的扩展性十分优异。
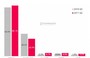
然而,针对Intel之说法,NVIDIA提出了强烈的反驳,并于部落格中撰文指出,Intel使用的是18个月前的Caffe AlexNet数据,比较的是四个Maxwell GPU和四个Xeon Phi处理器。如果使用更新的Caffe AlexNet数据,就会发现四个Maxwell GPU比四个Xeon Phi处理器的速度快30%。事实上,采用四个Pascal架构的TITAN X GPUs,其训练速度比四个Xeon Phi处理器快90%,而若采用新款DGX-1系统,更是快了5倍多。NVIDIA也补充,对于深度学习训练,与其使用大量的弱节点,还不如使用少量的强节点,效果会更好。
无论两边引用数据基准为何,从上述双方的隔空交火可看出,随着人工智慧的重要性日益增加,晶片大厂间的竞争也更加激烈,用以强化自身优势的策略也越来越多,如Intel除推出新系列Xeon Phi处理器,也于之前购并Nervana,强化其软体演算能力,相信未来的人工智慧市场,还会再掀起更多波澜。








 公安机关备案号:
公安机关备案号:


